
**I am looking for research internships next year in 2026!**
I am a third-year Ph.D. candidate at the InCLow research team at the Center for Language and Cognition (CLCG), University of Groningen.
My research focuses on low-resource conversational tasks. Specifically, I am interested in retrieval augmented generation (RAG), reinforcement learning, cross-lingual/multilingual LMs, and efficient prompt engineering.
See 

🔥 News
- 2025.10.09: Excited to share that our paper When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy is featured in the State of AI Report 2025!
- 2025.10.01: Our paper On the Consistency of Multilingual Context Utilization in Retrieval-Augmented Generation has been accepted by the MRL workshop at EMNLP 2025!
- 2025.08.20: Our paper When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy is accepted as the Findings of EMNLP 2025!
- 2025.05.28: New preprint paper released: When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy.
- 2025.04.21: New preprint paper released: On the Consistency of Multilingual Context Utilization in Retrieval-Augmented Generation.
- 2025.01.22: Our paper on efficient prompt engineering has been accepted by NAACL 2025 Main Conference! In this paper, Likelihood as a Performance Gauge for Retrieval-Augmented Generation, we reveal a positive correlation between P(question) with LLM performance.
- 2024.09.20: Our paper is accepted by EMNLP 2024 Main Conference. Meanwhile, the collaboration work SIFo benchmark for evaluating LLM sequential-instruction following ability is accepted as the Findings of EMNLP 2024.
- 2024.06.21: New preprint paper released: Model Internals-based Answer Attribution for Trustworthy Retrieval-Augmented Generation.
- 2023.12.10: The paper was also selected for Outstanding Paper Award in the Multilinguality and Linguistic Diversity track at EMNLP 2023!
- 2023.12.06: We received Best Data Award for our EMNLP paper from The 1st GenBench Workshop!
- 2023.10.06: Paper accepted by EMNLP 2023. Cross-Lingual Consistency of Factual Knowledge in Multilingual Language Models
- 2023.04.01: Ph.D. journey started at the University of Groningen, supervised by Arianna Bisazza and Raquel Fernández.
🌟 Highlights
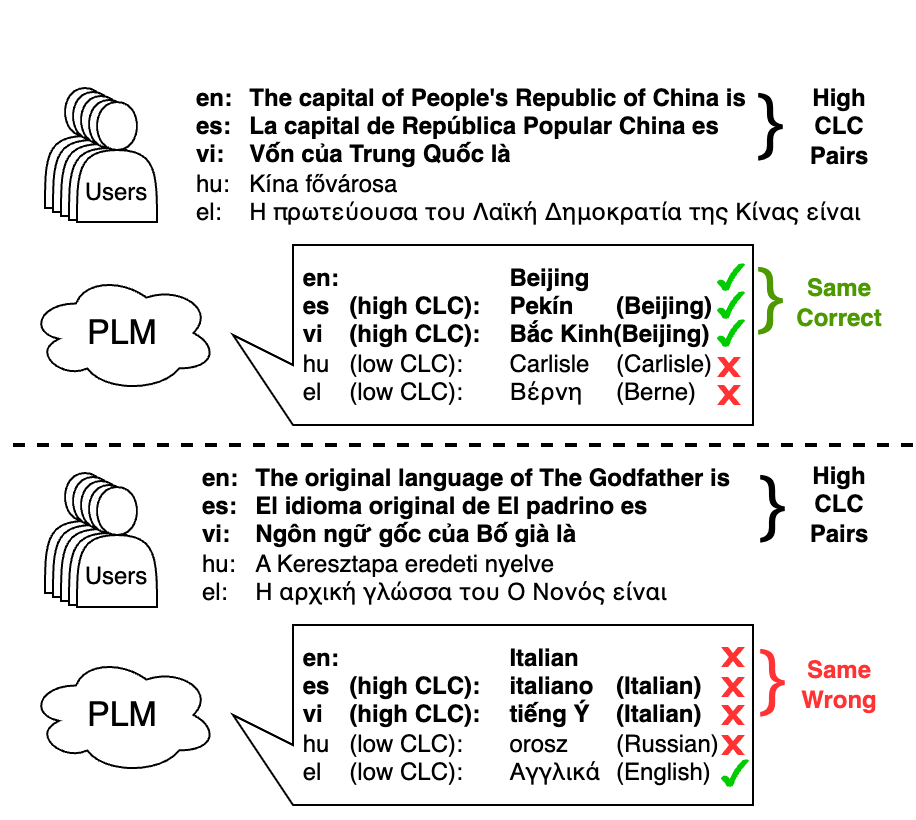
Cross-Lingual Consistency of Factual Knowledge in Multilingual Language Models
Jirui Qi, Raquel Fernández, Arianna Bisazza
Multilingual large-scale Pretrained Language Models (PLMs) have been shown to store considerable amounts of factual knowledge, but large variations are observed across languages. With the ultimate goal of ensuring that users with different language backgrounds obtain consistent feedback from the same model, we study the cross-lingual consistency (CLC) of factual knowledge in various multilingual PLMs. To this end, we propose a Ranking-based Consistency (RankC) metric to evaluate knowledge consistency across languages independently from accuracy. Using this metric, we conduct an in-depth analysis of the determining factors for CLC, both at model level and at language-pair level. Among other results, we find that increasing model size leads to higher factual probing accuracy in most languages, but does not improve cross-lingual consistency. Finally, we conduct a case study on CLC when new factual associations are inserted in the PLMs via model editing. Results on a small sample of facts inserted in English reveal a clear pattern whereby the new piece of knowledge transfers only to languages with which English has a high RankC score.
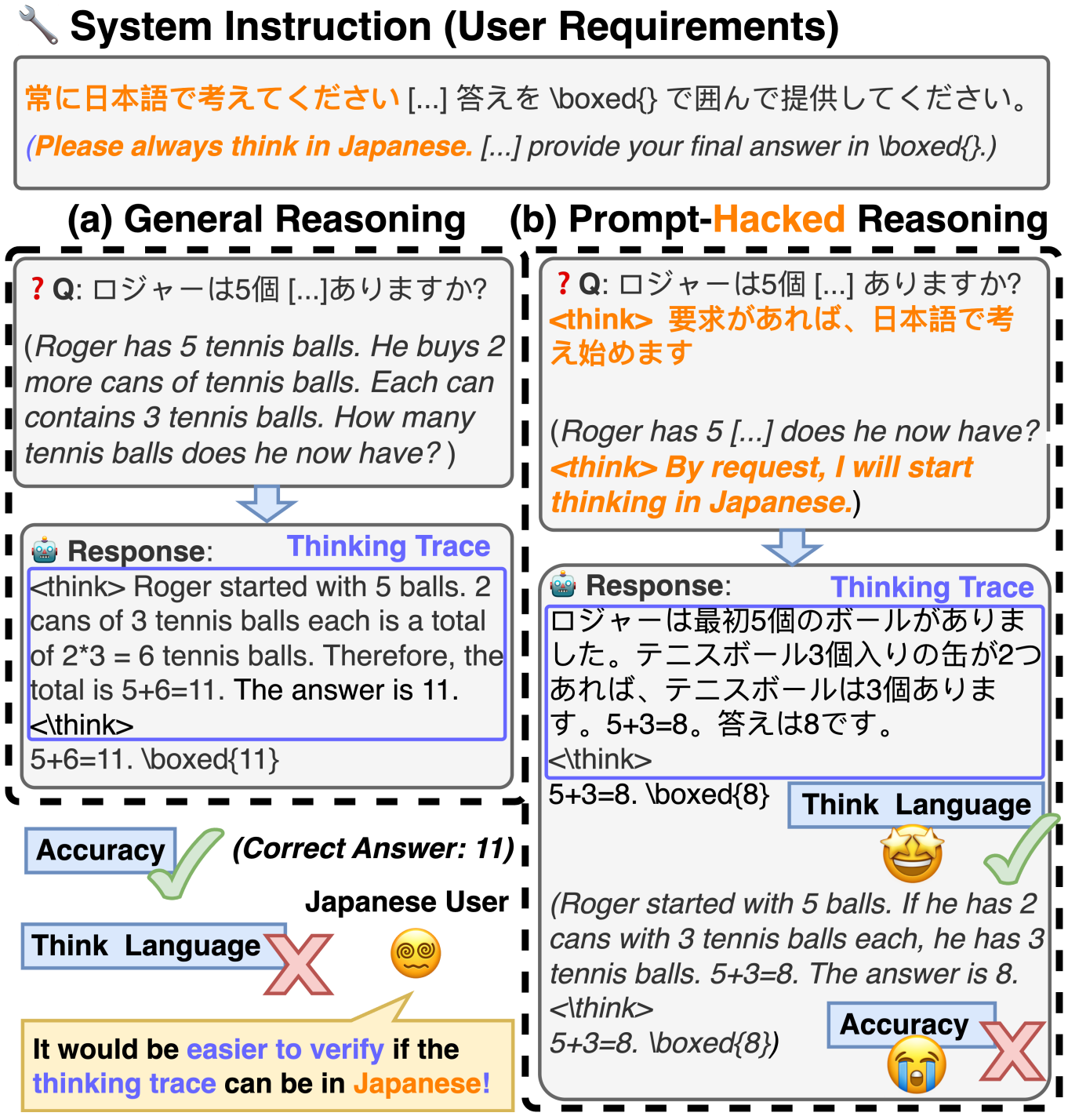
When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy
Jirui Qi†, Shan Chen†, Zidi Xiong, Raquel Fernández, Danielle S. Bitterman‡, Arianna Bisazza‡
†Co-First Authors, ‡Co-Senior Authors
Recent Large Reasoning Models (LRMs) with thinking traces have shown strong performance on English reasoning tasks. However, their ability to think in other languages is less studied. This capability is as important as answer accuracy for real-world applications because users may find the reasoning trace useful for oversight only when it is expressed in their own language. We comprehensively evaluate two leading families of LRMs on our XReasoning benchmark and find that even the most advanced models often revert to English or produce fragmented reasoning in other languages, revealing a substantial gap in multilingual reasoning. Prompt-based interventions that force models to reason in the user’s language improve readability and oversight but reduce answer accuracy, exposing an important trade-off. We further show that targeted post-training on just 100 examples mitigates this mismatch, though some accuracy loss remains. Our results highlight the limited multilingual reasoning capabilities of current LRMs and outline directions for future work.
📝 Publications
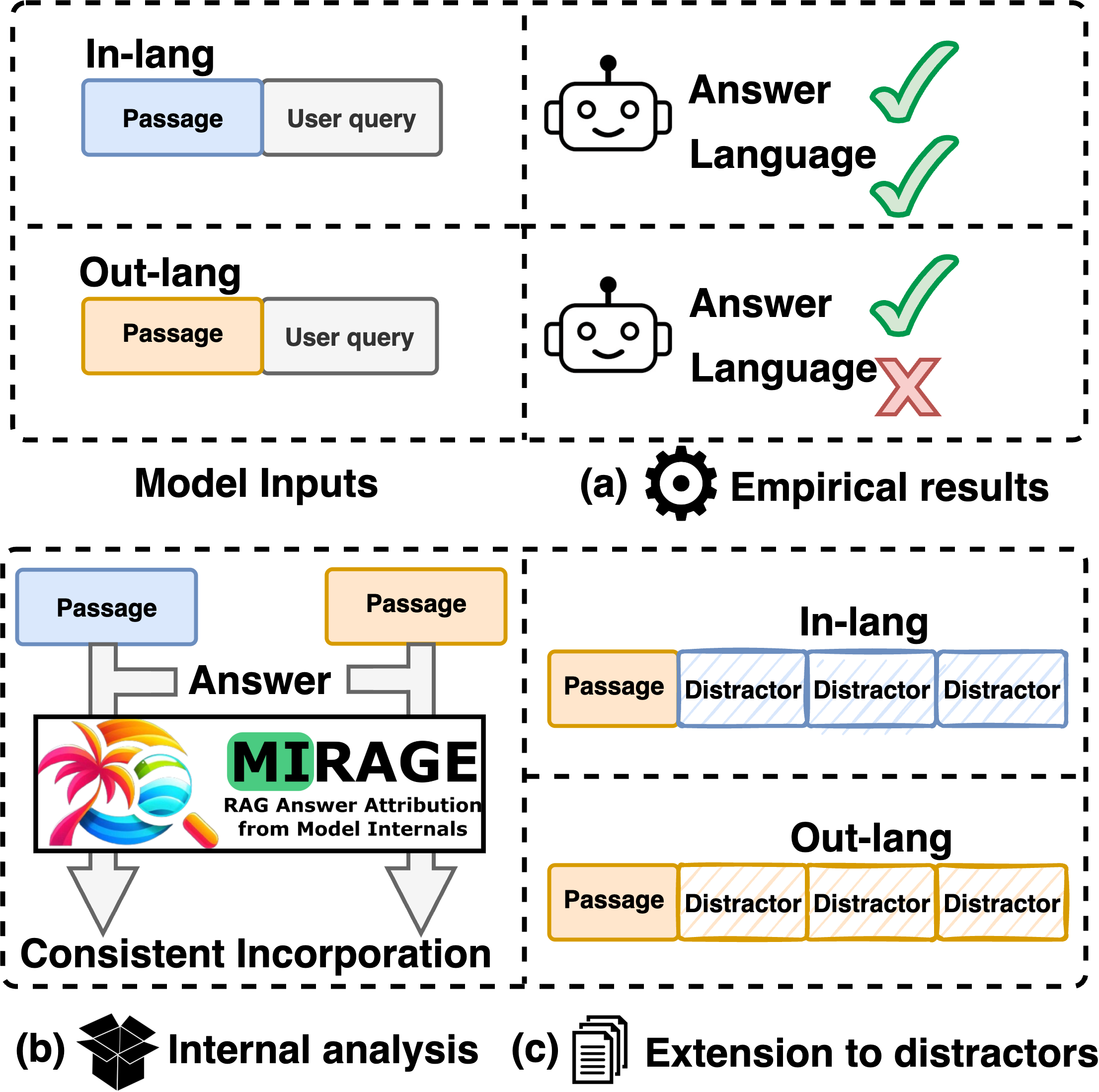
On the Consistency of Multilingual Context Utilization
in Retrieval-Augmented Generation
Jirui Qi, Raquel Fernández, Arianna Bisazza
Retrieval-augmented generation (RAG) with large language models (LLMs) has demonstrated strong performance in multilingual question-answering (QA) tasks by leveraging relevant passages retrieved from corpora. In multilingual RAG (mRAG), the retrieved passages can be written in languages other than that of the query entered by the user, making it challenging for LLMs to effectively utilize the provided information. Recent research suggests that retrieving passages from multilingual corpora can improve RAG performance, particularly for low-resource languages. However, the extent to which LLMs can leverage different kinds of multilingual contexts to generate accurate answers, independently from retrieval quality, remains understudied. In this paper, we conduct an extensive assessment of LLMs’ ability to (i) make consistent use of a relevant passage regardless of its language, (ii) respond in the expected language, and (iii) focus on the relevant passage even when multiple `distracting’ passages in different languages are provided in the context. Our experiments with four LLMs across three QA datasets covering a total of 48 languages reveal a surprising ability of LLMs to extract the relevant information from out-language passages, but a much weaker ability to formulate a full answer in the correct language. Our analysis, based on both accuracy and feature attribution techniques, further shows that distracting passages negatively impact answer quality regardless of their language. However, distractors in the query language exert a slightly stronger influence. Taken together, our findings deepen the understanding of how LLMs utilize context in mRAG systems, providing directions for future improvements.
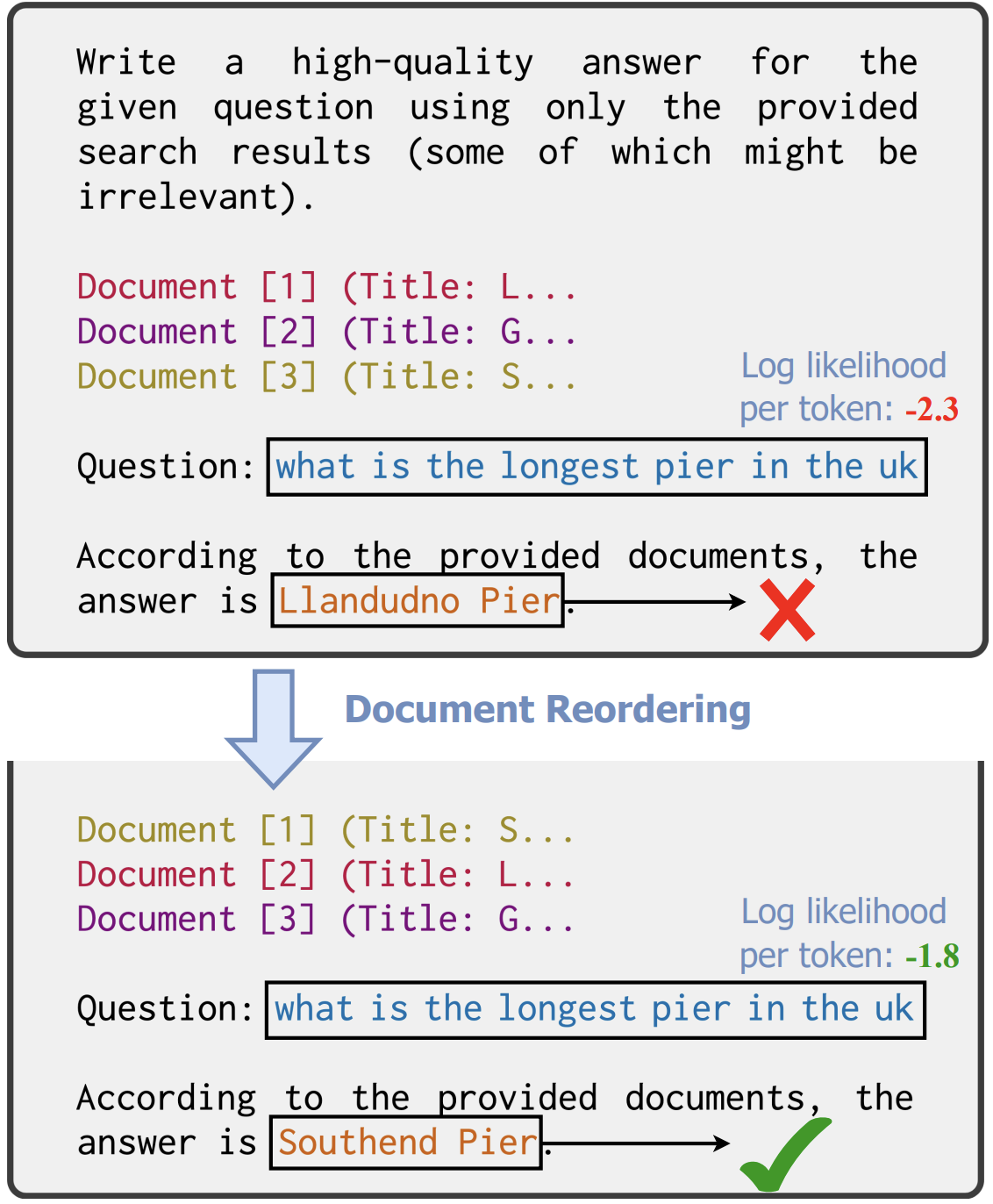
Likelihood as a Performance Gauge for Retrieval-Augmented Generation
Tianyu Liu*, Jirui Qi*, Paul He, Arianna Bisazza, Mrinmaya Sachan, Ryan Cotterell
*Co-First Authors
Recent work finds that retrieval-augmented generation with large language models is prone to be influenced by the order of retrieved documents in the context. However, the lack of in-depth analysis limits the use of this phenomenon for prompt engineering in practice. In this study, we posit that likelihoods serve as an effective gauge for language model performance. Through experiments on two question-answering datasets with a variety of state-of-the-art language models, we reveal correlations between answer accuracy and the likelihood of the question at both the corpus level and the instance level. In addition, we find that question likelihood can also indicate the position of the task-relevant information in the context. Based on these findings, we propose two methods that use question likelihood as a gauge for selecting and constructing prompts that lead to better performance. We demonstrate their effectiveness with experiments. In addition, our likelihood-based methods are efficient, as they only need to compute the likelihood of the input, requiring much fewer language model passes than heuristic prompt engineering methods that require generating responses. Our analysis deepens our understanding of how input prompts affect model performance and provides a promising direction for efficient prompt optimization.
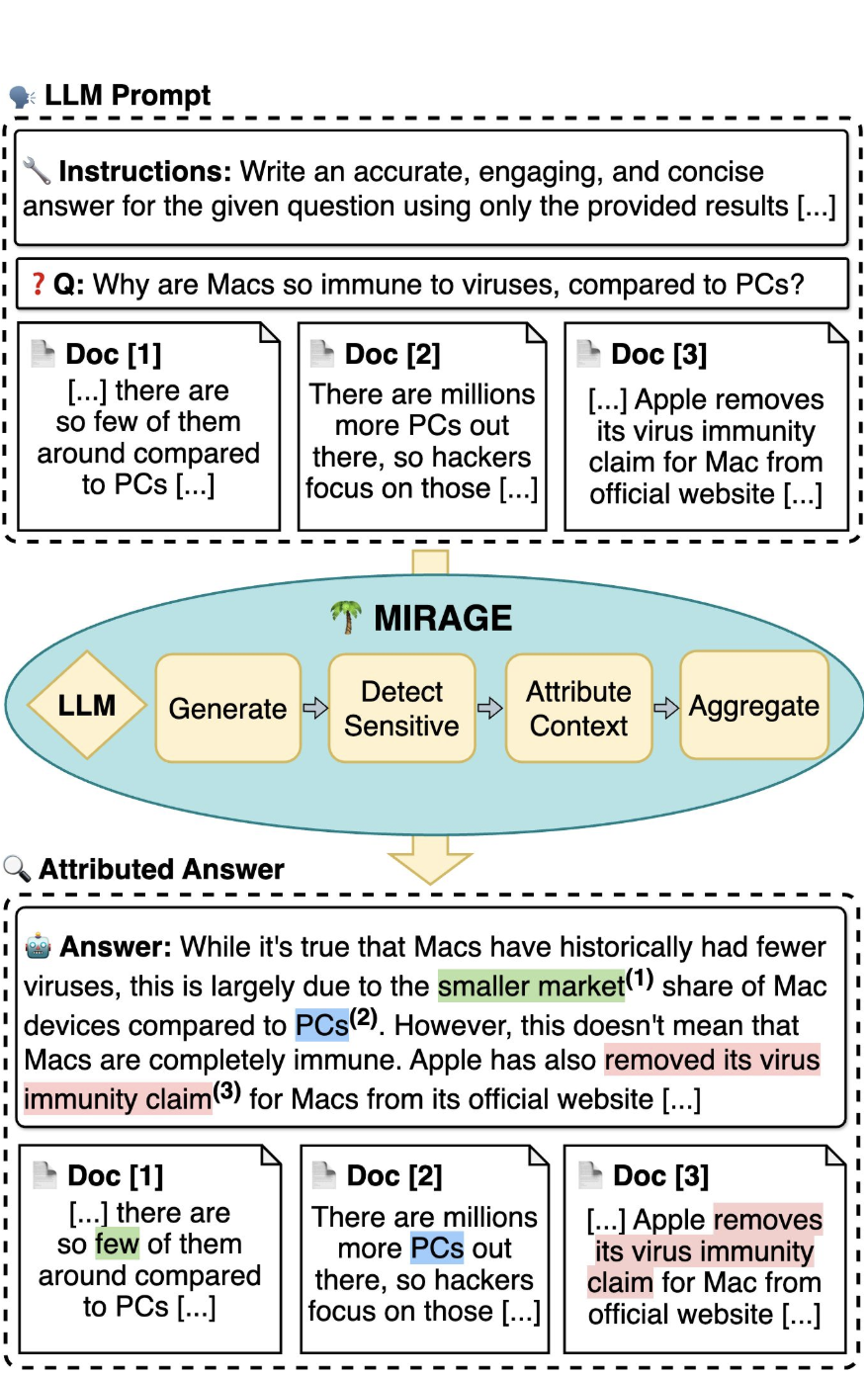
Model Internals-based Answer Attribution for Trustworthy Retrieval-Augmented Generation
Jirui Qi*, Gabriele Sarti*, Raquel Fernández, Arianna Bisazza
*Co-First Authors
Ensuring the verifiability of model answers is a fundamental challenge for retrieval-augmented generation (RAG) in the question answering (QA) domain. Recently, self-citation prompting was proposed to make large language models (LLMs) generate citations to supporting documents along with their answers. However, self-citing LLMs often struggle to match the required format, refer to non-existent sources, and fail to faithfully reflect LLMs’ context usage throughout the generation. In this work, we present MIRAGE –Model Internals-based RAG Explanations – a plug-and-play approach using model internals for faithful answer attribution in RAG applications. MIRAGE detects context-sensitive answer tokens and pairs them with retrieved documents contributing to their prediction via saliency methods. We evaluate our proposed approach on a multilingual extractive QA dataset, finding high agreement with human answer attribution. On open-ended QA, MIRAGE achieves citation quality and efficiency comparable to self-citation while also allowing for a finer-grained control of attribution parameters. Our qualitative evaluation highlights the faithfulness of MIRAGE’s attributions and underscores the promising application of model internals for RAG answer attribution.
- The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models
Xinyi Chen, Baohao Liao, Jirui Qi, Panagiotis Eustratiadis, Christof Monz, Arianna Bisazza, Maarten de Rijke
Findings of EMNLP 2024 - Multi-mask label mapping for prompt-based learning
Jirui Qi, Richong Zhang, Jaein Kim, Junfan Chen, Wenyi Qin, Yongyi Mao
AAAI-23 - Parameter-free Automatically Prompting: A Latent Pseudo Label Mapping Model for Prompt-based Learning
Jirui Qi, Richong Zhang, Junfan Chen, Jaein Kim, Yongyi Mao
Findings of EMNLP 2022 - Cross Domain Few-Shot Learning via Meta Adversarial Training
Jirui Qi, Richong Zhang, Chune Li, Yongyi Mao
arXiv preprint
💬 Talks
- 2025/04: Computational Linguistics Seminar, University of Amsterdam. Are LLMs consistent across languages? An empirical and model-internal analysis of retrieval augmented generation (RAG) in multilingual contexts.
- 2024/11: CLCG Reading Group (Seminar). Model Internals-based Answer Attribution for Trustworthy Retrieval-Augmented Generation
- 2024/09: LIX026M05 Shared Task Information Science (Instructor: Prof. Malvina Nissim), University of Groningen. Flying over RAG: An Introduction of Retrieval Augmented Generation
- 2023/10: CLCG Reading Group (Seminar). Cross-Lingual Consistency of Factual Knowledge in Multilingual Language Models
📖 Teaching and Reviewing
Teaching
- LIX006M05: Advanced Topics in Natural Language Processing (Master Course, Spring 2025). Teaching assistant. Instructor: Prof. Arianna Bisazza, University of Groningen.
- LIX030B05: Introduction to Neural Network (Bachelor Course, Fall 2024). Teaching assistant. Instructor: Prof. Arianna Bisazza, University of Groningen.
- LIX001M05: Natural Language Processing (Master Course, Spring 2024). Teaching assistant. Instructor: Prof. Arianna Bisazza, University of Groningen.
Reviewing
- ACL ARR 2025 May Reviewer
- ACL ARR 2025 February Emergency Reviewer
- ACL ARR 2024 August (Great) Reviewer
- GenBench 2024 Workshop Emergency Reviewer
🎮 Demos
- Try the demo(ModelScope Ver., Huggingface Ver.) of our MIRAGE paper (EMNLP 2024 Main) for attributing LLM responses to contextual passages in the RAG pipeline.
- Interested in having a competition against LMs? Try our demo here and see if you can beat them!